AI-First na vida real - gestão, método e a realidade de quem tem AI em escala em produção
(TL;DR): AI não é mágica, é engenharia e gestão de risco. Comece pelo problema, tenha um processo top-down, faça discovery decente, escolha quando usar AI (e quando NÃO usar), meça, documente e itere. O resto é fumaça.
O hype e a realidade
Vamos a ela: a famosa, a incrível, a disruptiva, a tecnologia que mais produziu “especialistas” nos últimos anos, a Inteligência Artificial. Como passar por 2025 sem falar do assunto? Depois de ondas como no/low-code, realidade aumentada/mista e blockchain, chegamos ao novo “tema que vai mudar o futuro”.
Sim, AI tem potencial gigantesco e não começou ontem, a história remonta aos anos 1950. A diferença é que hoje conseguimos combinar poder computacional, dados, capital e produtos (alguns com AI, muitos apenas sobre AI).
O problema? Levar para produção. A alta liderança e investidores precisam entender que não se trata de truque; é método estatístico, engenharia de dados e resolução de problemas. E não, nem todo profissional virará “Vibe Coder” criador de múltiplos agentes.

Como todo hype, termos técnicos sofrem deturpação. De repente, tudo vira “agente”, e qualquer fluxo determinístico ganha um requisito de GenAI sem ninguém saber o porquê muito menos o qual problema resolver.
AI é caixa de ferramentas: martelo, furadeira, Excel, regressão logística, LLM, RAG, agente, regra de negócio… Nem todo problema precisa da mesma ferramenta. Você pode usar o martelo para o parafuso, funciona, mas o resultado não será o melhor, nem no tempo certo.
Perguntas de ouro:
- Que problema estamos resolvendo?
- Quais dores queremos sanar?
- No médio prazo, AI encaixa aqui de forma sustentável?
O que chamamos de AI-First (de verdade)
AI-First não é “colocar AI no centro do produto e pronto”. Isso é o mínimo. O difícil é entender, planejar e decidir quando faz sentido usar. Cultura ≠ feature.
Na Pier falamos de AI-First desde 2021. Depois de muitas iterações e modelos testados, aprendemos algumas coisas práticas:
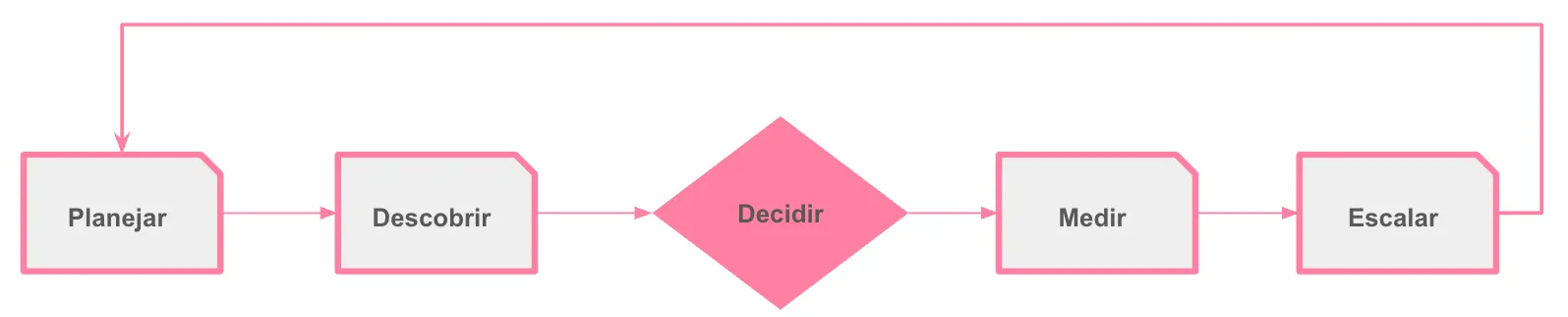
Começa top-down (e continua bottom-up)
- Treinamento e letramento (literacy): parta do princípio de que muita gente não usa AI no dia a dia, e quem usa, costuma tratar como “Google turbinado”. Ensine método (do problema ao prompting), riscos e limites.
- Pontos focais: eleja pessoas que se destaquem para disseminar conhecimento nas áreas. Elas aceleram cases locais e criam massa crítica.
- Evite centralização sufocante: um time central pode liderar a frente, mas se a AI não se espalhar por times e rotinas, não vira cultura.

Processo simples, claro e imperfeito (melhor que o PowerPoint perfeito)
Cada empresa é única. Dá para se inspirar em Google, Uber, Spotify — ou Pier — mas você vai adaptar. Comece do básico e itere.
Planejamento (OKRs, metas e prioridades)
Liste projetos candidatos a AI. Você vai errar em vários, tudo bem. O filtro real vem com discovery e dados.
Discovery de verdade (com PoC curta)
Teste viabilidade rapidamente. Às vezes um if/else ou uma regressão resolvem a V1 melhor que um LLM. Use o que te deixa mais rápido: ChatGPT, Gemini, DeepSeek… Não invente moda de ferramenta se o caminho curto existe.
Decisão dura: AI agora ou depois?
Precisa de time-to-market? Dá para lançar com regra enquanto coleta dados, prepara infraestrutura, feature store, MCP etc., e chegar com AI robusta em 3–6 meses? Muitas vezes, sim. Regra na V1, AI na V2, e dados desde o dia 1.
Metas, acompanhamento e documentação
Sem monitoramento, tudo quebra rápido. Defina metas, SLOs e gatilhos: quando subir nova versão, quando mudar processo, quando seu modelo driftar.
Documente o essencial: objetivo, decisões, dados, modelos, pipelines, código/low-code, riscos e plano de rollback.
Volte ao começo e escale por áreas
No ciclo de metas, deixe as ideias aparecerem (design thinking on). Filtre depois pelo valor e viabilidade e pelo fit com AI.
Guia de bolso: “Isso é mesmo um caso de AI?”
Use AI quando:
- Variabilidade alta de linguagem/conteúdo (texto, imagem, documento);
- Regras explodem em complexidade ou recall precisa ser maior que precision na triagem;
- O custo de errar é baixo a moderado e há como human-in-the-loop;
- Você tem dados ou pode coletá-los de forma sustentável.
Evite AI quando:
- O problema tem regra clara e dados estruturados já cobrem 80%+;
- O custo de erro é alto e não há contenção/validação;
- Não existe métrica de sucesso objetiva (ou ninguém vai medir…).
Métricas que importam (para gestão e para devs)
Negócio
- Uplift vs. baseline (ex.: redução de TMA, aumento de aprovação, diminuição de custo por caso);
- Adoção por fluxo/área; NPS/CES quando aplicável.
Produto/Operação
- Latência p95/p99; taxa de fallback; taxa de intervenção humana;
- Taxa de cobertura (quanto do problema passa pelo fluxo com AI).
Modelo/Qualidade
- Win-rate em avaliação A/B; métricas de offline eval (ex.: F1, exact match, BLEU/ROUGE quando fizer sentido);
- Drift de dados (PSI/KL simples); hallucination rate em amostras auditadas.
Custo e risco
- Custo por chamada/sessão; custo por caso resolvido;
- Incidentes de segurança (prompt injection, data leakage) e bloqueios bem-sucedidos.
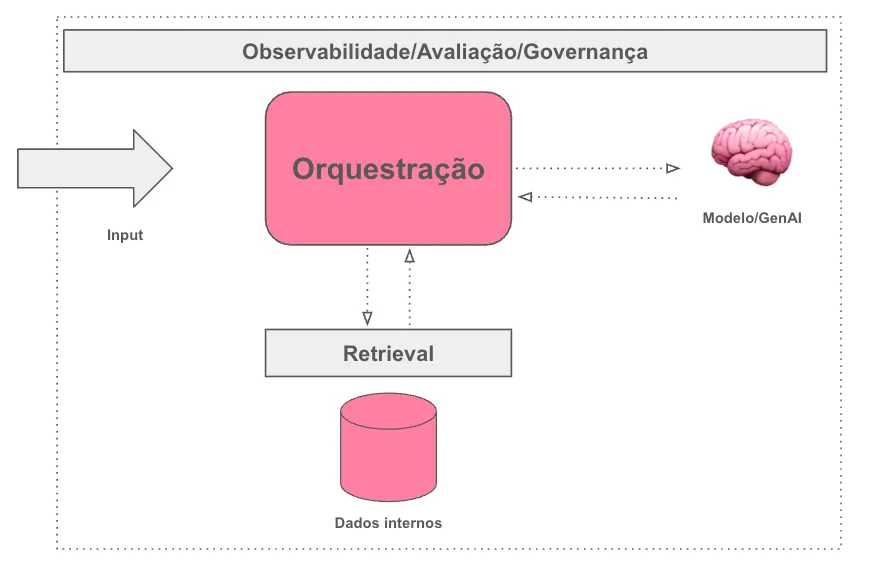
Arquitetura mínima viável (para não começar torto)
- Entrada: captura de contexto + validações;
- Retrieval (quando houver conhecimento): indexação → RAG com guardrails;
- Orquestração: router simples (regra/LLM), fallbacks e timeouts;
- Avaliação: trace de chamadas, offline evals automatizadas e testes de regressão;
- Observabilidade: logs de prompt/resposta com PII safe, dashboards e alertas;
- Governança: catálogo de dados e política de retenção.
Anti-padrões (aprendidos do jeito difícil)
- “Agente para tudo” — fluxos simples pedem soluções simples.
- PoC eterna — sem hipótese, métrica e cutline, é só demo bonita.
- Sem dono — se todo mundo é dono, ninguém é.
- Sem dados — garbage in, garbage out ainda é verdade.
- Sem evals — sem tests, não há regressão, só sensação.
- Centralização sufocante — o time central vira gargalo e mata a cultura.
Template rápido de PDR - Quais respostas responder?
- Problema e sucesso: qual dor? como saberei que resolvi?
- Dados: fontes, qualidade, lacunas e plano de coleta;
- Abordagem: Regra/Algoritmo/LLM/RAG/Agente? Por quê? Alternativas consideradas;
- Métricas & riscos: cutlines, guardrails e plano de rollback;
- Entrega: escopo V1 (com ou sem AI), cronograma, donos e dependências;
- Observabilidade: logs, tracing, dashboards e alertas;
- Documentação: onde vive, quem atualiza, quando revisamos?
Exemplo de roteiro de adoção em 3 Fases
Fase 1
- Nomeie sponsor executivo e champions por área;
- Defina 3–5 problemas com retorno potencial (e risco controlado);
- Configure tracing e boas práticas mínimas de dados.
Fase 2
- Faça PoCs de 1–2 semanas por problema;
- Compare Regra vs. AI com métrica clara;
- Escolha 1–2 para V1.
Fase 3
- Lance V1 (mesmo que com regra) com coleta de dados;
- Programe as revisões quinzenais;
- Prepare V2 com AI se os dados e as métricas justificarem.
Conclusão
AI-First é cultura, método e execução. Comece pequeno, escolha bem suas batalhas, meça sem dó e documente. O resto é fumaça (e threads no LinkedIn).
- Sim, AI pode reduzir custo. Não, não vai substituir três departamentos na terça-feira.
- Sim, LLMs erram. Não, isso não te libera de medir e colocar guardrails.
- Sim, dá para começar leve. Não, não dá para pular documentação.
Sim, uma AI ajudou a organizar este texto. Não, ela não escreveu por mim, serviu apenas como ferramenta, como deveria ser.